
网站信息收集
指纹信息
网站指纹
指纹的定义:网站指纹是通过收集和分析网站的技术特征,确定其使用了那些技术组件:
前端:如 HTML、CSS、JavaScript 框架(React、Vue、Angular 等)
后端:如 PHP、Java、Python、Go 等编程语言
中间件:如 Apache、Nginx、JBoss、WebLogic、Caddy、IIS、Tengine、东方通、宝兰德等
操作系统:如 Linux(Ubuntu、CentOS 等)、Windows
后端开发框架:如 Spring Boot、Django、Flask、Gin、ThinkPHP 等
CMS 内容管理系统:如 WordPress、Discuz!、Hexo、织梦 CMS、Drupal、Joomla 等
开发组件:
- 搜索引擎:Elasticsearch、Solr
- JSON 解析引擎:Jackson、Fastjson
- 安全框架:Spring Security、Apache Shiro
- 日志记录框架:Log4j2、Logback
- 数据库连接池/ORM 框架:MyBatis、Hibernate、Alibaba Druid、C3P0
- 编辑器:FCKeditor、Kindeditor、UEditor
数据库:如 MySQL、Redis、PostgreSQL、MongoDB、Oracle 等
WAF(Web 应用防火墙):如雷池 WAF、安全狗、云锁、G01、宝塔等
OA(办公自动化系统):如泛微 OA、通达 OA、用友 OA、金蝶 OA、致远 OA、金和 OA、禅道 OA、蓝凌 OA 等
其他·········
为什么要收集指纹
收集网站指纹的目的是为了全面了解目标网站的技术构成,以便:
- 漏洞挖掘:通过识别网站使用的技术组件,结合已知的历史漏洞数据库,尝试发现潜在的安全漏洞。例如,若网站使用 Log4j2 和 Spring Boot,可以检查是否存在 Log4j2(如 CVE-2021-44228)或 Spring Boot 的历史漏洞。
- 安全加固:了解技术栈后,可以针对性地修复已知漏洞或优化配置。
相关工具:
- OA 漏洞脚本工具:提供针对 OA 系统的漏洞扫描脚本。
指纹收集工具
[!tip]
指纹收集工具的效果取决于其 指纹库 的覆盖范围和更新频率。建议选择活跃维护、指纹库全面的工具,并结合多种工具以提高识别准确率。
| 工具名称 | 描述 |
|---|---|
| kscan | 一款纯 go 开发的全方位扫描器 |
| AlliN | 一个辅助平常渗透测试项目或者攻防项目快速打点的综合工具 |
| observer_ward | 一款 Web 应用和服务指纹识别工具 |
| 棱洞 (EHole) | 一款红队重点攻击系统指纹探测工具 |
| Wappalyzer | 浏览器插件,用于快速识别网站技术栈 |
目录探测
概述
目录探测是通过扫描网站的路径结构,发现隐藏的目录、文件或接口。常见的探测目标包括:
- 网站备份文件(如
.tar.gz、.zip、.bak)。 - 管理后台页面(如
/admin、/login)。 - 敏感接口(如
/api、/actuator)。 - 配置文件或日志文件。
目录爆破
目录爆破是使用预定义的字典文件(包含常见目录和文件名)对网站进行逐一访问,寻找有效路径。
常用工具
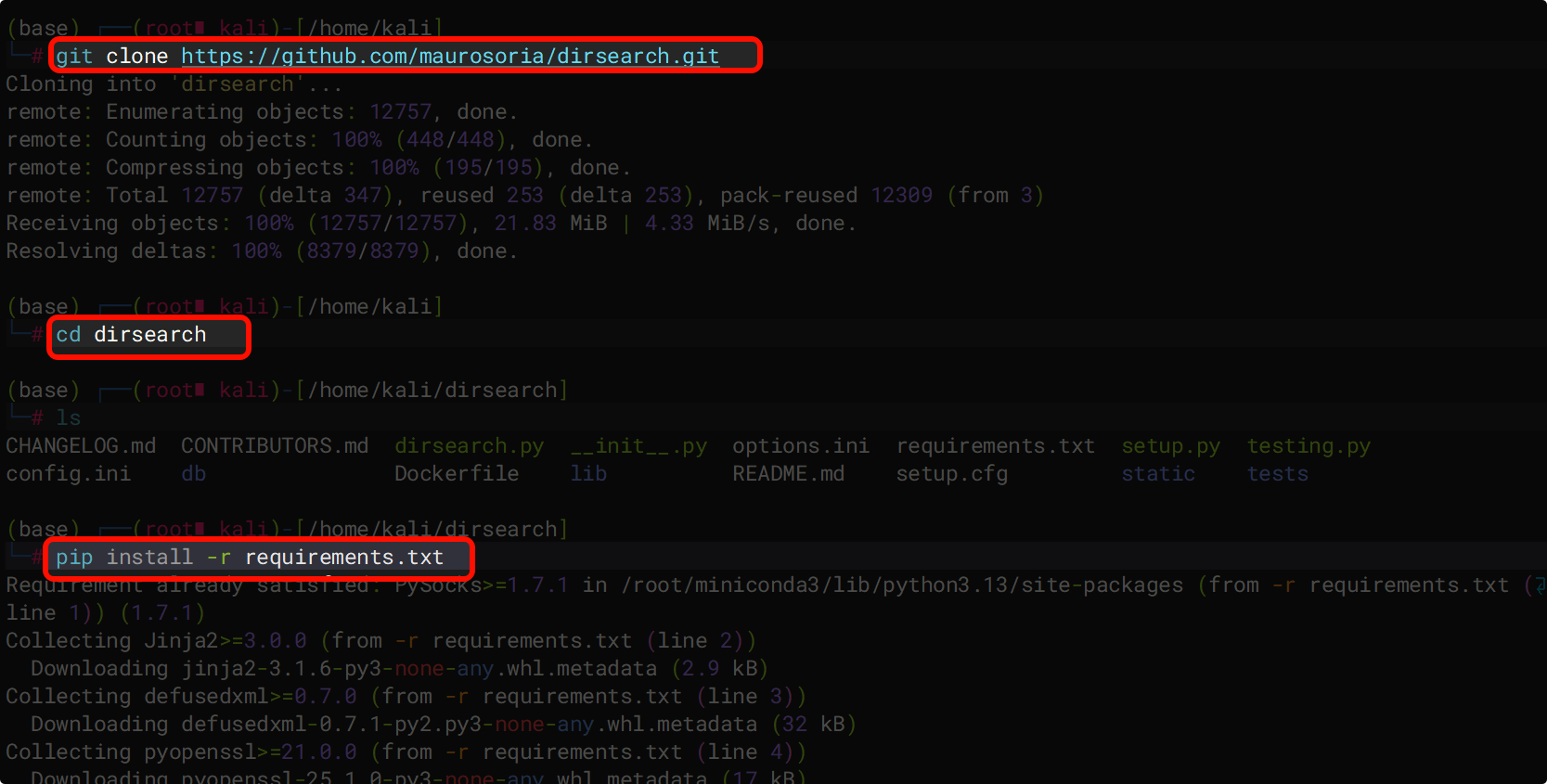
- dirsearch:一款高效的目录扫描工具,支持多线程和自定义字典。
#下载
git clone https://github.com/maurosoria/dirsearch.git
#安装相关依赖库
cd dirsearch
pip install -r requirments.txt
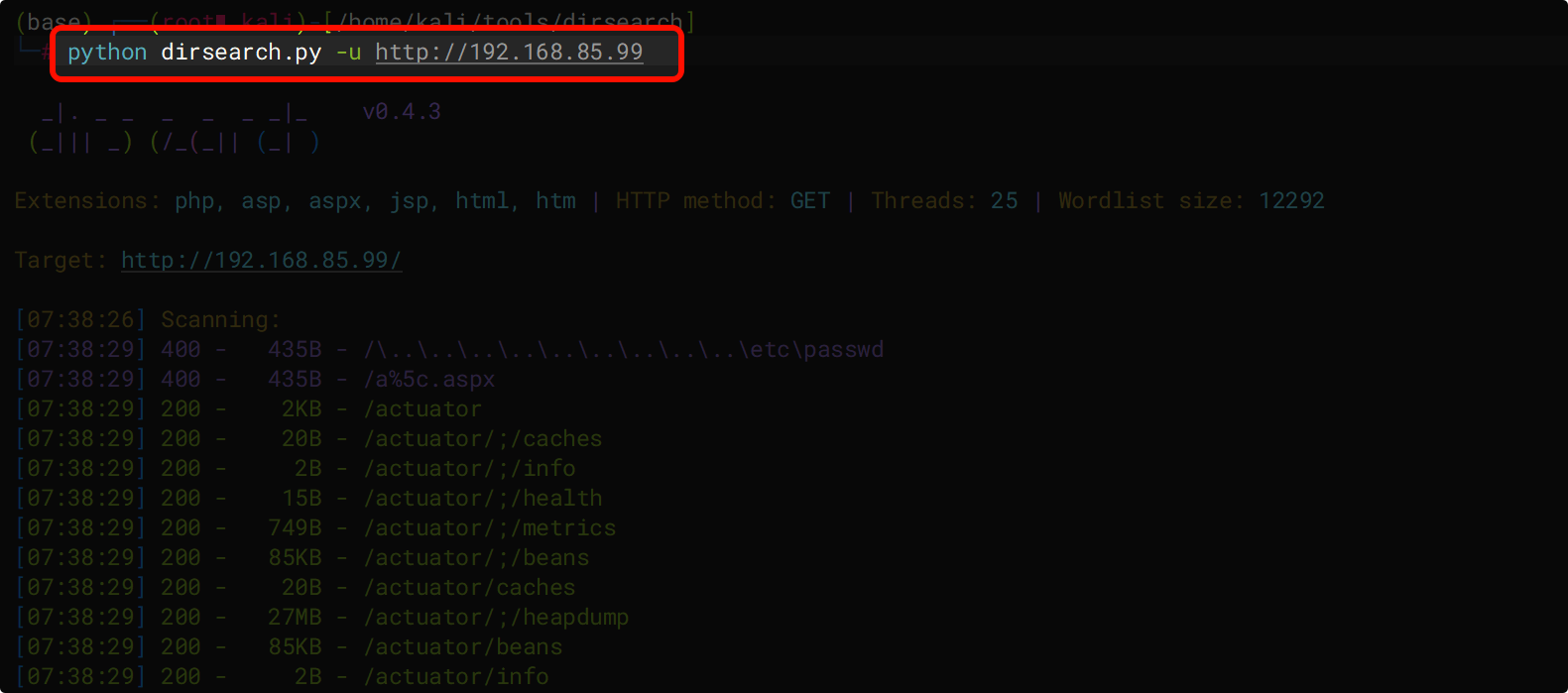
#扫描网站
python dirsearch.py -u "URL"
值得关注的目录和文件
备份文件:
- 文件类型:
.tar、.tar.gz、.zip、.bak - 风险:直接访问可能触发下载,泄露网站源码、数据库配置或其他敏感信息。
- 文件类型:
Git 泄露:
原因:开发者写的代码,一般都会传到 github 中,但是开发者在生产环境中未删除
.git目录,导致版本控制信息暴露。#初始化 git git init #把自己写的代码追加到 git 中 git add .风险:可通过工具还原部分或全部源代码。
工具:dumpall
#通过 git 泄露尝试还原网站的后端代码 python dumpall.py -u http://192.168.2.147:18080/.git/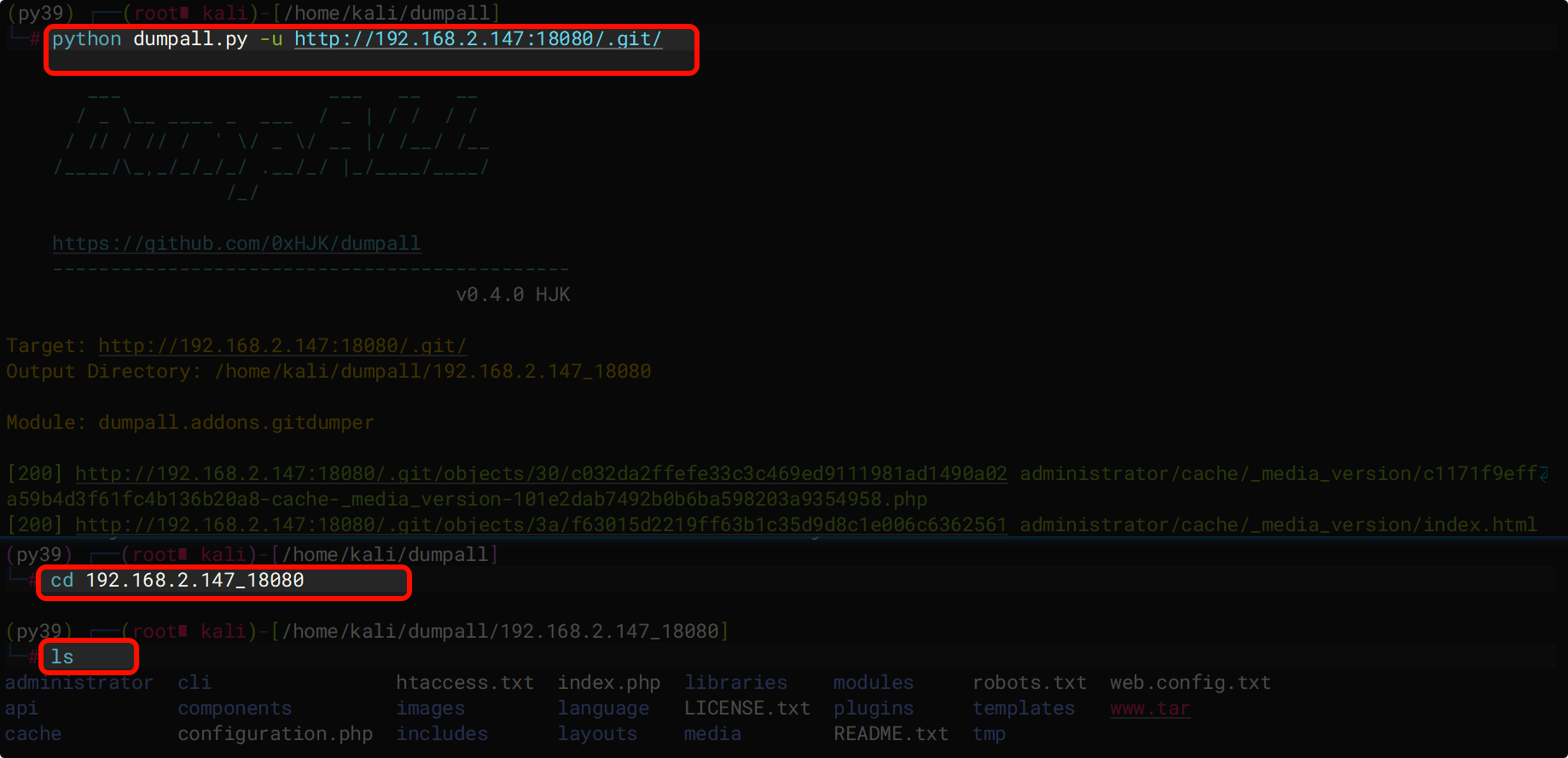
获取源码的处理方式:
- 查找敏感信息(如数据库用户名密码、API 密钥、JWT 密钥等)。
- 进行代码审计,寻找逻辑漏洞或硬编码凭据。
Spring Boot Actuator 信息泄露:
常见接口:
/actuator、/actuator/env、/actuator/heapdump。风险:
/actuator/env:泄露环境变量,可能包含密钥或配置信息。/actuator/heapdump:泄露 JVM 字节码,访问接口会触发下载,可用于进一步分析。
工具:
- SpringBoot-Scan:扫描 Spring Boot 的敏感信息泄露端点,并直接测试 Spring 的相关高危漏洞
- 前端助手 FeHelper:JSON 自动格式化工具
- JDumpSpider:HeapDump 敏感信息提取工具
示例:搭建 Spring Boot Actuator 信息泄露靶场
- 构建 Dockerfile
#选择基础镜像 FROM openjdk:8u342-jre #把应用程序的 JAR 文件复制到容器中 COPY ./spring_actuator_demo-0.0.1-SNAPSHOT.jar /spring_actuator_demo.jar #开放80端口 EXPOSE 80 #运行 java -jar /spring_actuator_demo.jar CMD [ "java", "-jar", "/spring_actuator_demo.jar" ]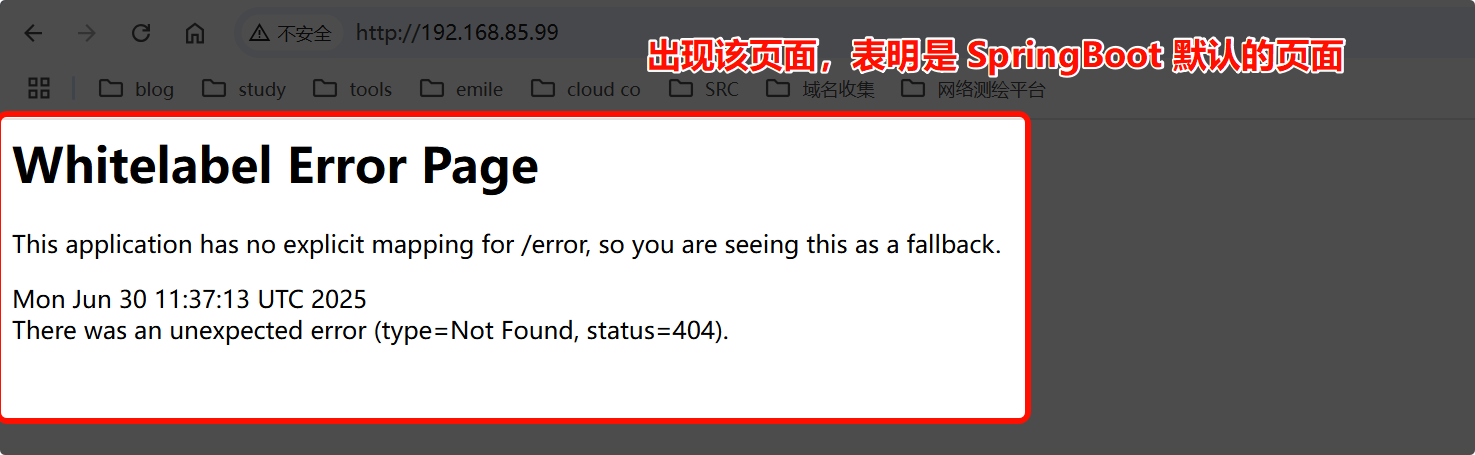
爬取目录:
python dirsearch.py -u http://192.168.85.99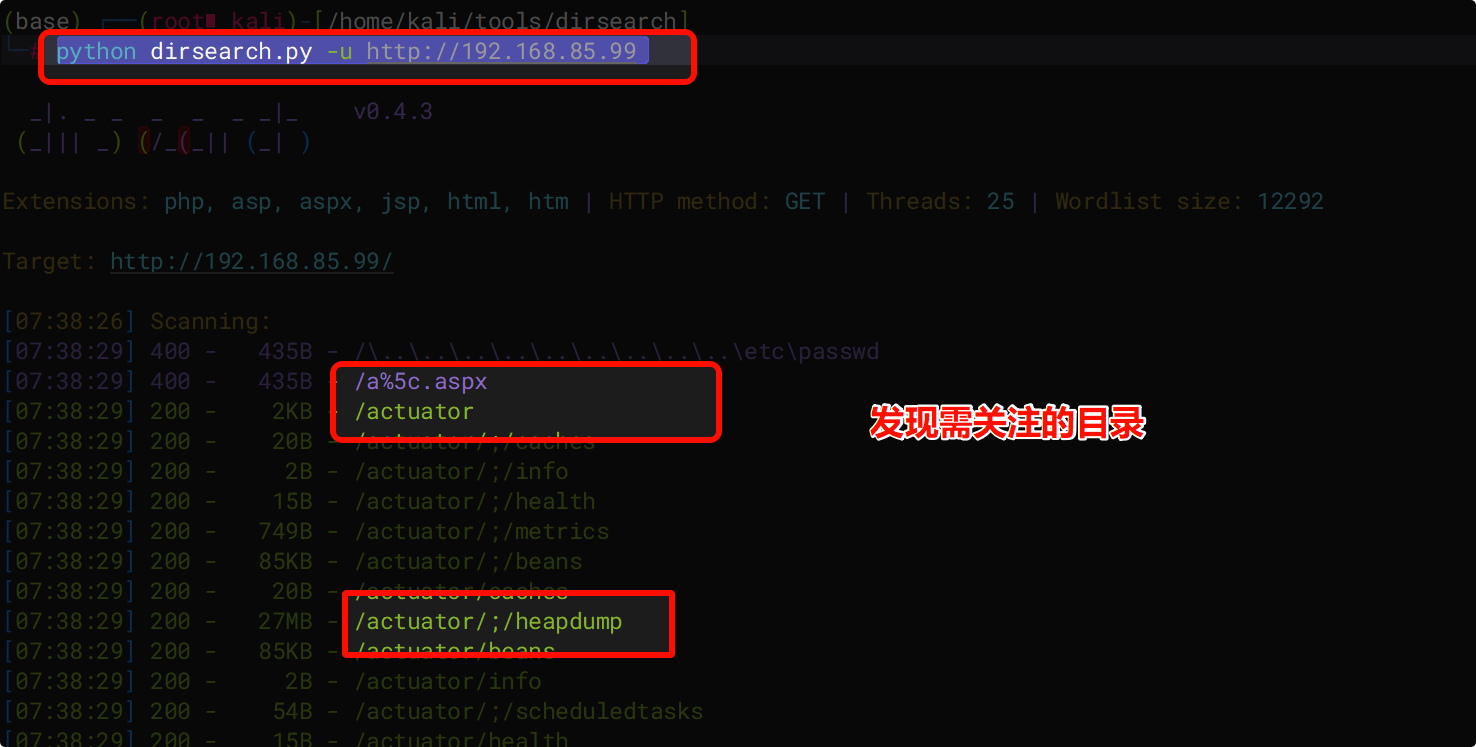
借助浏览器插件 前端助手 FeHelper 查看页面:
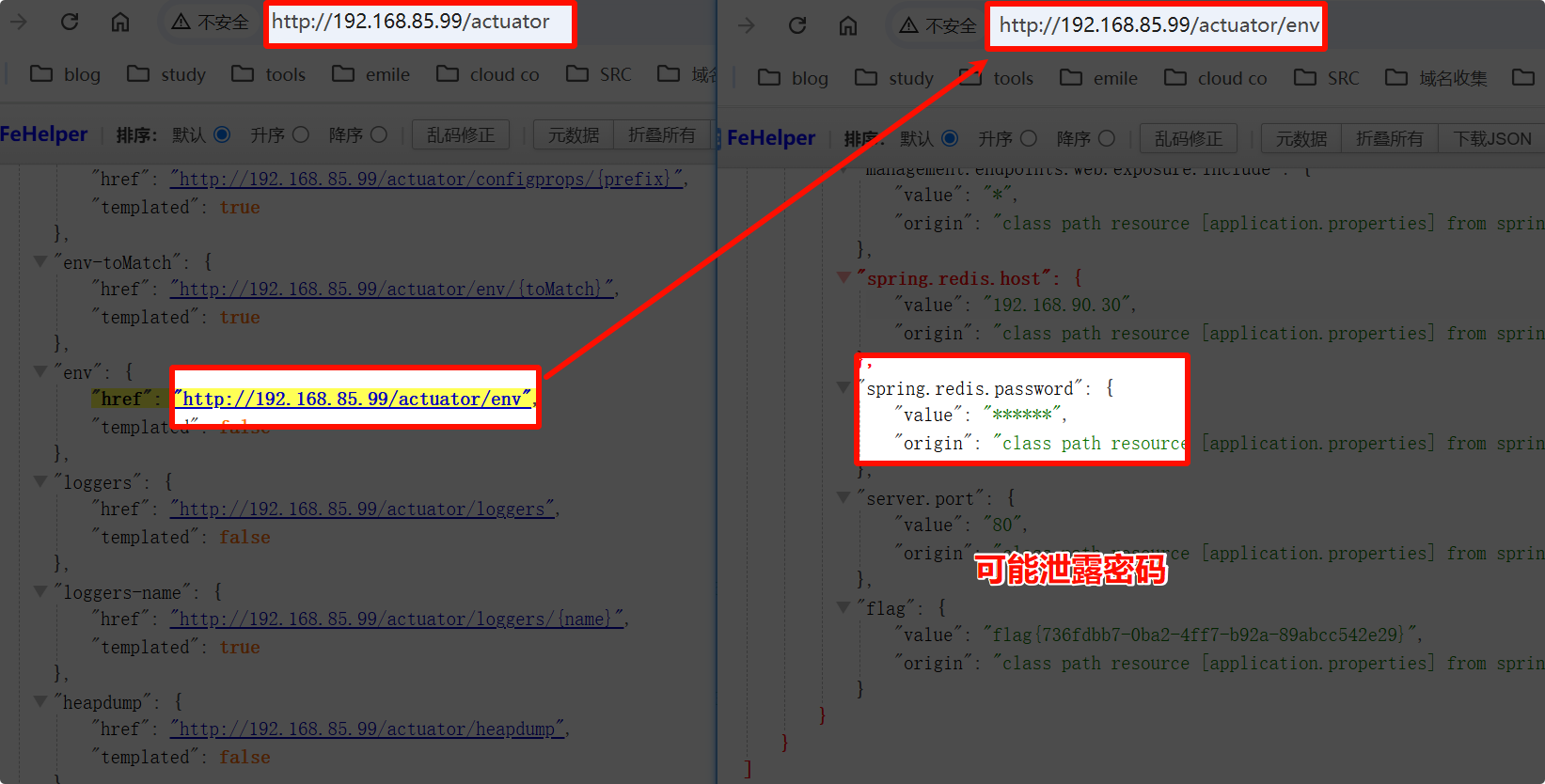
/actuator/heapdump目录泄露 jvm 字节码,访问接口会触发下载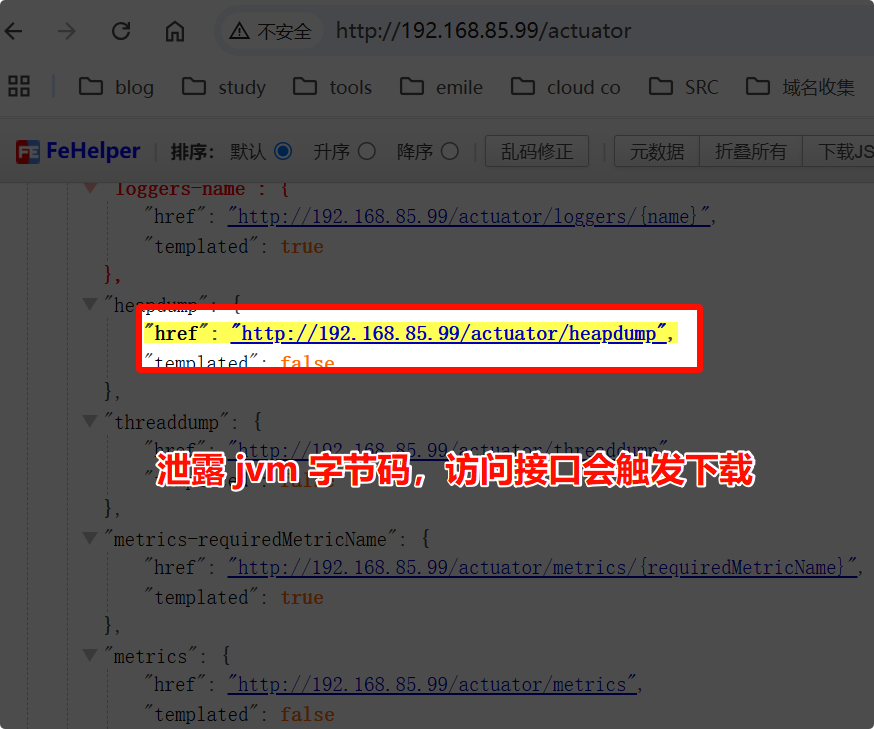
利用 JDumpSpider 解析字节码,在下载的 heapdump 文件中提取敏感信息:
java -jar JDumpSpider-1.1-SNAPSHOT-full.jar [heapdump文件路径]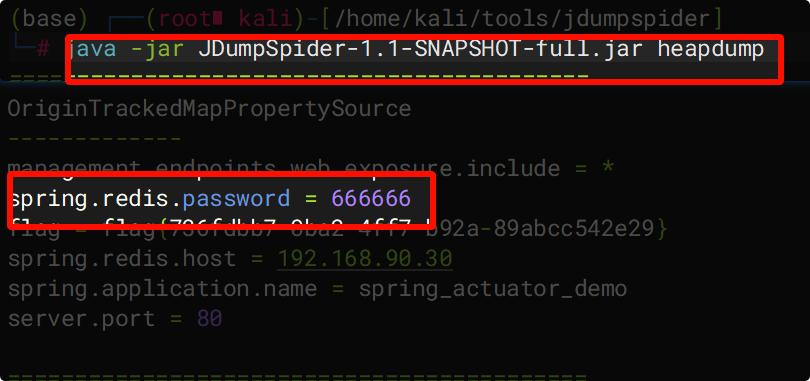
其他敏感文件:
- 日志文件、后台页面、各种敏感接口(文件上传、文件下载)、个人敏感信息泄露(身份证号、手机号)。
- 接口文档:如
/api-docs、/swagger-ui.html,可能暴露 API 结构。 - robots.txt:定义爬虫规则(不允许爬虫获取哪个页面),可能泄露隐藏路径。
- DS_Store:macOS 文件索引,可能包含目录结构。
- SVN 泄露:类似 Git 泄露,可能暴露代码仓库。
检查敏感信息工具:BurpSuite 插件 RouteVulScan
使用方法:
- 打开 Burp Suite 的 Dashboard 扫描器。
- 运行 RouteVulScan。
- 访问目标网站,Burp Suite 抓包时插件会自动扫描。
爬虫与 URI 提取
爬虫
爬虫用于获取网站结构,收集所有可访问的页面和链接。常用工具包括:
- Scrapy:Python 爬虫框架,适合复杂网站。
- Crawley:轻量级爬虫工具,适合快速抓取。
- BurpSuite:

URI 提取
在前后端分离的开发模式下,后端通常提供 RESTful API(如 /api/user/getInfoById),前端通过 AJAX 或 Axios 等 javascript 请求这些接口,浏览器中会留下大量的后端接口信息,URI 提取工具可以捕获这些接口信息。
工具:
findsomething:浏览器插件,提取页面中的 API 请求。
- 注意:启用插件可能影响网站正常请求,把插件改成点击插件时才运行。
- 局限:对非 API 驱动的网站(如传统 MVC 或 Node.js 渲染)效果有限。
JSFinder:专门提取 JavaScript 文件中的 API 路径。
使用场景:识别未公开的 API 接口,可能包含未授权访问点。
其他敏感信息提取
常见敏感信息类型
- 个人隐私信息:身份证号、手机号、邮箱等。
- 配置文件:如
.env、application.yml,可能包含数据库凭据或密钥。 - 日志文件:可能记录用户输入或错误信息。
- 接口文档:如 Swagger UI,可能暴露 API 设计细节。
敏感信息提取工具
HaE
- Burp Suite 插件,自动高亮显示页面中的敏感信息(如密钥、ID 号)。

Google 黑客语法
- 利用 Google 搜索引擎查找公开的敏感信息,参考 Google Dorks
- 结合时间筛选进行查询,可能更易
- 常见语法:
| 语法 | 用途 | 示例 |
|---|---|---|
| site: | 搜索特定网站或域名 | site: example.com |
| intitle: | 搜索标题中含关键词的页面 | intitle: "login" |
| inurl: | 搜索 URL 中含特定字符串的页面 | inurl: admin |
| intext: | 搜索网页正文中含特定文本的页面 n | intext: "password" |
| filetype: | 搜索特定文件类型 | filetype: pdf、filetype: xls |
| ext: | 按文件扩展名搜索 | ext: env DB_PASSWORD |
| AND / OR | 逻辑与 / 或 | intitle: login OR intitle: admin |
| – | 排除关键词 | intext: password -site: example.com |
| * | 通配符(匹配任意字符) | inurl:*.php?id = |
| "…" | 精确匹配短语 | "username and password" |
| cache: | 查看 Google 缓存的页面 | cache: example.com |
| related: | 查找类似网站 | related: example.com |
| define: | 查找定义 | define: hacking |
| info: | 获取网站信息 | info: example.com |
| allintext: | 搜索正文中包含所有关键词的页面 | allintext: "admin" "dashboard" |
| allintitle: | 搜索标题中包含所有关键词的页面 | allintitle: "index of" "backup" |
| allinurl: | 搜索 URL 中包含所有关键词的页面 | allinurl: admin/login |
历史网站快照
- 通过 Wayback Machine 查看网站历史版本,可能发现已删除的敏感页面或文件。
GitHub 搜索
GitHub 是开发者常用的代码托管平台,可能包含泄露的敏感信息(如密钥、配置文件)。搜索技巧包括:
- 使用关键词搜索:如
AWSSecretKey。 - 参考:GitHub Leaked Secrets。


